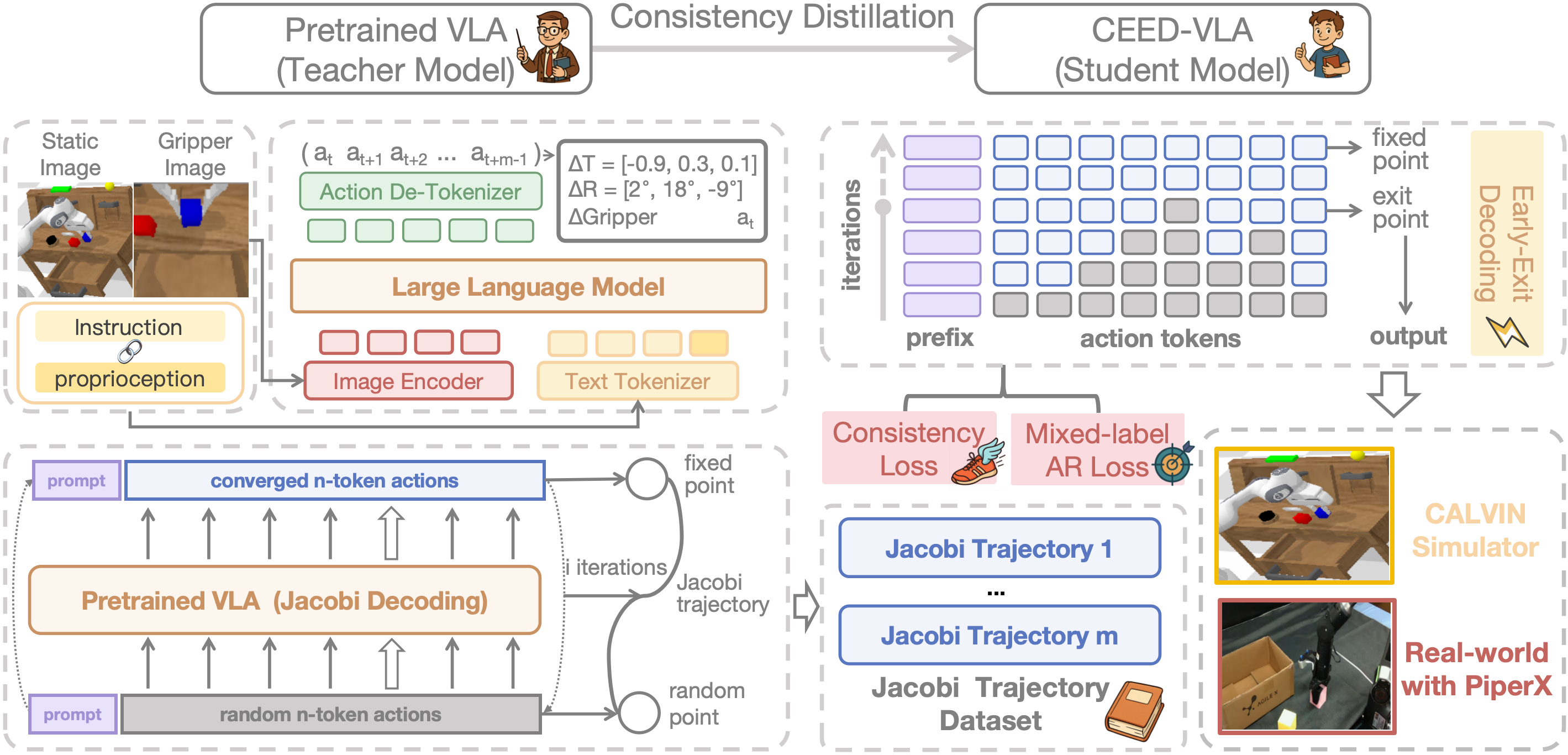
The architecture of CEED-VLA with consistency distillation and early-exit decoding.

The Jacobi trajectory collection process.
For the target VLA \( P \), we let \( Q_\theta(\cdot \mid \mathbf{x}) \) denote the CEED-VLA model
with parameters \( \theta \) initialized from \( P \). To capture the inherent consistency within Jacobi trajectories,
we first collect them by prompting \( P \) to predict actions using Jacobi decoding on the robot dataset \( \mathcal{C} \).
Consistency Training
The consistency training procedure optimizes two objectives:
(i) guiding the model to predict multiple correct tokens simultaneously, and
(ii) constraining CEED-VLA from drifting away from the target VLA distribution to preserve manipulation skills.
1. Consistency Loss
We design a consistency loss to ensure that any intermediate point \( \mathcal{Y} \) on the Jacobi trajectory \( \mathcal{J} \) is mapped to the fixed point \( \mathcal{Y}^* \). This encourages the model to converge efficiently.
\[
\mathcal{L}_{\text{C}} = \mathbb{E}_{(\mathbf{x}, \mathcal{J}) \sim \mathcal{D}, \mathcal{Y} \sim \mathcal{J}} \left[ \sum_{i=1}^n \text{KL}\left( Q_{\theta^{-}}(\cdot|\mathcal{Y}_i^*, \mathbf{x}) \,\|\, Q_{\theta}(\cdot|\mathcal{Y}_i, \mathbf{x}) \right) \right]
\]
where \( \theta^{-} = \text{stopgrad}(\theta) \) and KL denotes the forward KL divergence.
2. Mixed-label AR Supervision
To maintain autoregressive behavior, we retain the AR loss from the teacher model:
$$
\mathcal{L}_{\text{AR}} = \mathbb{E}_{(\mathbf{x}, \mathcal{Y}^{*}) \sim \mathcal{D}} \left[ -\sum_{i=1}^N \log Q_{\theta}\left( \mathcal{Y}^{*}_{i} \mid \mathcal{Y}^{*}_{\lt i}, \mathbf{x} \right) \right]
$$
For outliers with large deviation (measured by L1 distance), the AR labels are replaced by corresponding ground-truth values.
3. Total Loss
\[
\mathcal{L}(\theta) = \mathcal{L}_{\text{C}} + \omega \cdot \mathcal{L}_{\text{AR}}
\]
where \( \omega \) is a weighting coefficient balancing consistency and AR supervision.
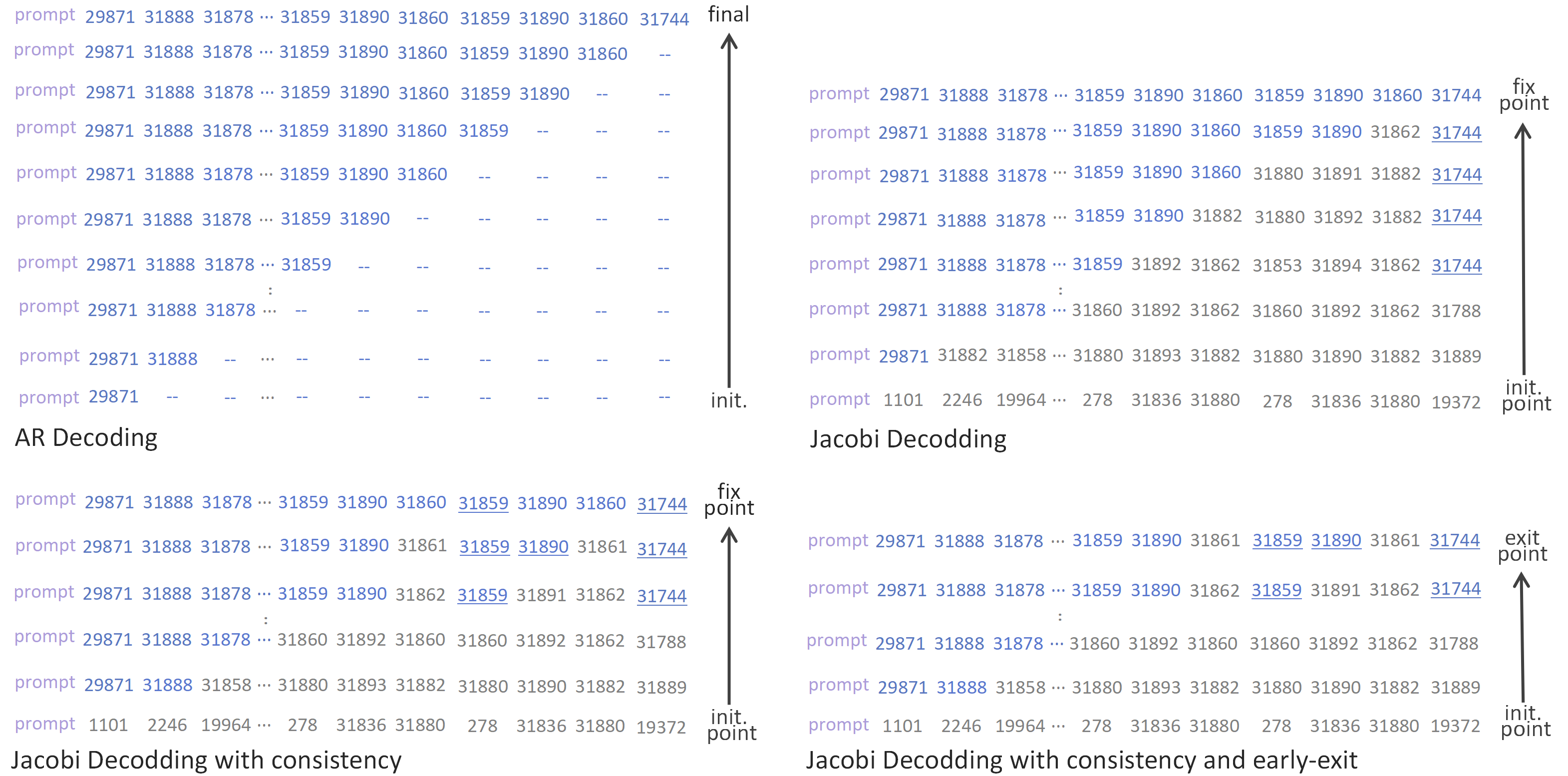
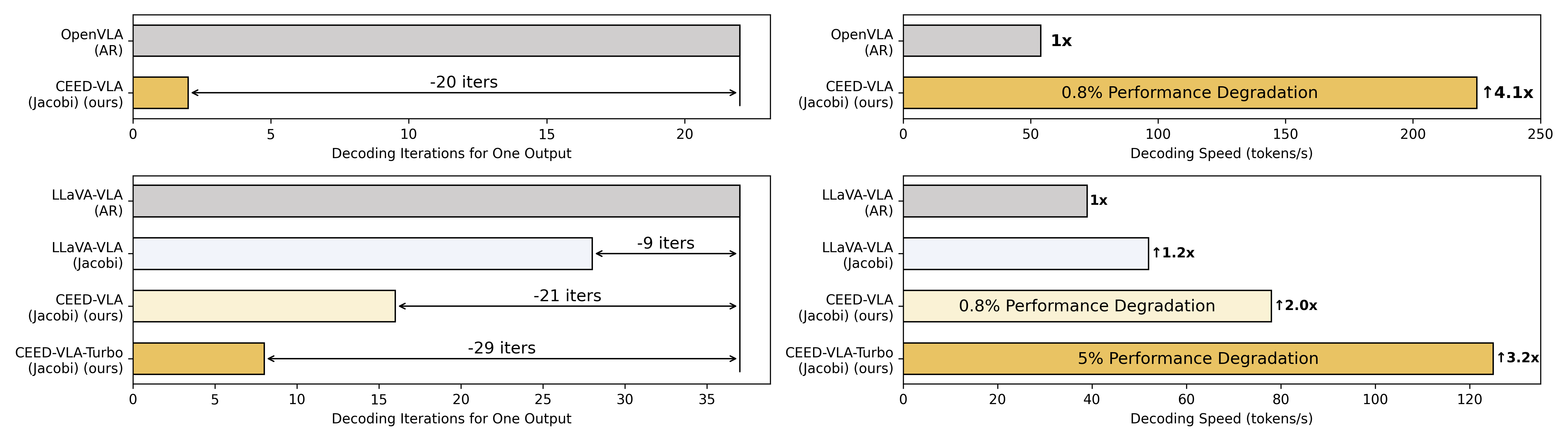
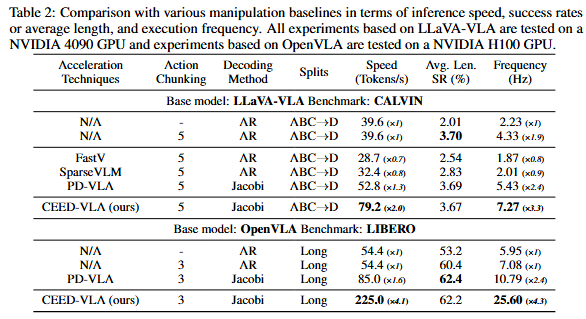
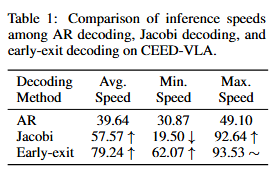
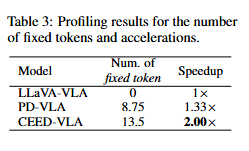
The comparison of four decoding methods.
To address the inefficiency of Jacobi decoding caused by strict convergence requirements, we propose early-exit decoding.
Instead of waiting for full convergence,the model exits early at a predefined step and directly outputs the intermediate result.
This strategy leverages the observation that late-stage token updates are often minor and have limited impact on task success.
By relaxing the stopping condition, early-exit decoding significantly improves both the average and minimum inference speeds while preserving manipulation accuracy, enabling high-frequency robotic control with minimal delay.